Executive Summary
Qwen3-Next represents a breakthrough in LLM architecture, achieving performance comparable to models 10x its active parameter size while maintaining extreme training and inference efficiency through innovative hybrid attention mechanisms and ultra-sparse MoE design.
Key Quote from Paper: “We believe that Context Length Scaling and Total Parameter Scaling are two major trends in the future of large models.”
Key Achievement: “This base model achieves performance comparable to (or even slightly better than) the dense Qwen3-32B model, while using less than 10% of its training cost (GPU hours). In inference, especially with context lengths over 32K tokens, it delivers more than 10x higher throughput — achieving extreme efficiency in both training and inference.”
Why This Matters
In the race to build more capable AI systems, we’ve hit a wall: models are getting too expensive to train and too slow to run. Qwen3-Next breaks through this barrier with a radical approach - what if we could have 80 billion parameters but only use 3 billion at a time?
Key Innovations at a Glance
| Innovation | Why It Matters in Practice |
|---|---|
| 75:25 GDNet:GA Hybrid | Prefill/decode scale efficiently on long contexts while GA preserves recall capabilities |
| 512 Experts, Top-10 | 3.75% activation (3B/80B) → massive FLOP savings while retaining model capacity |
| Partial RoPE (25%) | Better length extrapolation; reduces high-frequency position distortion |
| Zero-Centered Norm | Training stability; prevents weight drift and massive activations |
| Native MTP Support | Enables speculative decoding for faster inference (1.3-2.1× speedup potential) |
Core Architectural Innovations
The 75:25 Hybrid Attention Revolution
Qwen3-Next solves a fundamental trade-off in attention mechanisms:
- Linear attention is fast but weak at recall
- Standard attention is expensive and slow during inference
The solution? Mix Gated DeltaNet with standard attention at a 3:1 ratio (75% layers use Gated DeltaNet, 25% keep standard attention). This hybrid consistently outperforms any monolithic architecture — achieving both better performance and higher efficiency.
Gated DeltaNet (75% of Layers)
Linear attention transforms the traditional O(n²) attention complexity to O(n) by reformulating the attention mechanism. Instead of computing pairwise token interactions, it uses kernel tricks to approximate attention patterns.
# Complexity comparison
Standard Attention: O(n²) where n = sequence length
Gated DeltaNet: O(n) - linear scaling!Gated Attention (25% of Layers)
Standard attention excels at precise token recall and maintaining global context awareness, crucial for tasks requiring exact information retrieval. Enhancements include:
- Output gating to reduce low-rank issues
- Increased head dimension: 128 → 256
- Selective RoPE applied to only 25% of position dimensions
Ultra-Sparse MoE Architecture
Here’s where it gets wild:
- Total Parameters: 80 billion (all experts combined)
- Active Parameters: ~3 billion (3.75% activation rate)
- Result: Performance matching dense 32B models at less than 10% of the cost
Think of it as having specialized teams where only relevant experts work on each problem. The model maintains 512 experts but only activates the top-10 for each token - extreme specialization with extreme efficiency.
Training Stability Through Innovation
Attention Output Gating
Solves two critical problems:
- Attention Sink: Where attention weights concentrate heavily on specific tokens
- Massive Activations: Extremely large values causing gradient explosions
The solution: Gating mechanism that adaptively scales attention outputs.
Zero-Centered RMSNorm
Standard RMSNorm can cause weight drift over time. Zero-centering prevents this drift and improves training stability:
# Standard RMSNorm
output = x * scale / RMS(x)
# Zero-Centered RMSNorm (Qwen3-Next)
output = (x - mean(x)) * scale / RMS(x - mean(x))Multi-Token Prediction (MTP)
Instead of predicting one token at a time, MTP predicts multiple future tokens simultaneously:
Traditional: token₁ → token₂ → token₃ (3 forward passes)
MTP: token₁ → [token₂, token₃, token₄] (1 forward pass)Result: 1.3-2.1× speedup in generation with native support in SGLang and vLLM.
Performance Analysis
Efficiency Quote: “It uses less than 80% of the GPU hours needed by Qwen3-30A-3B, and only 9.3% of the compute cost of Qwen3-32B — while achieving better performance.”
📊 Visual Architecture Overview
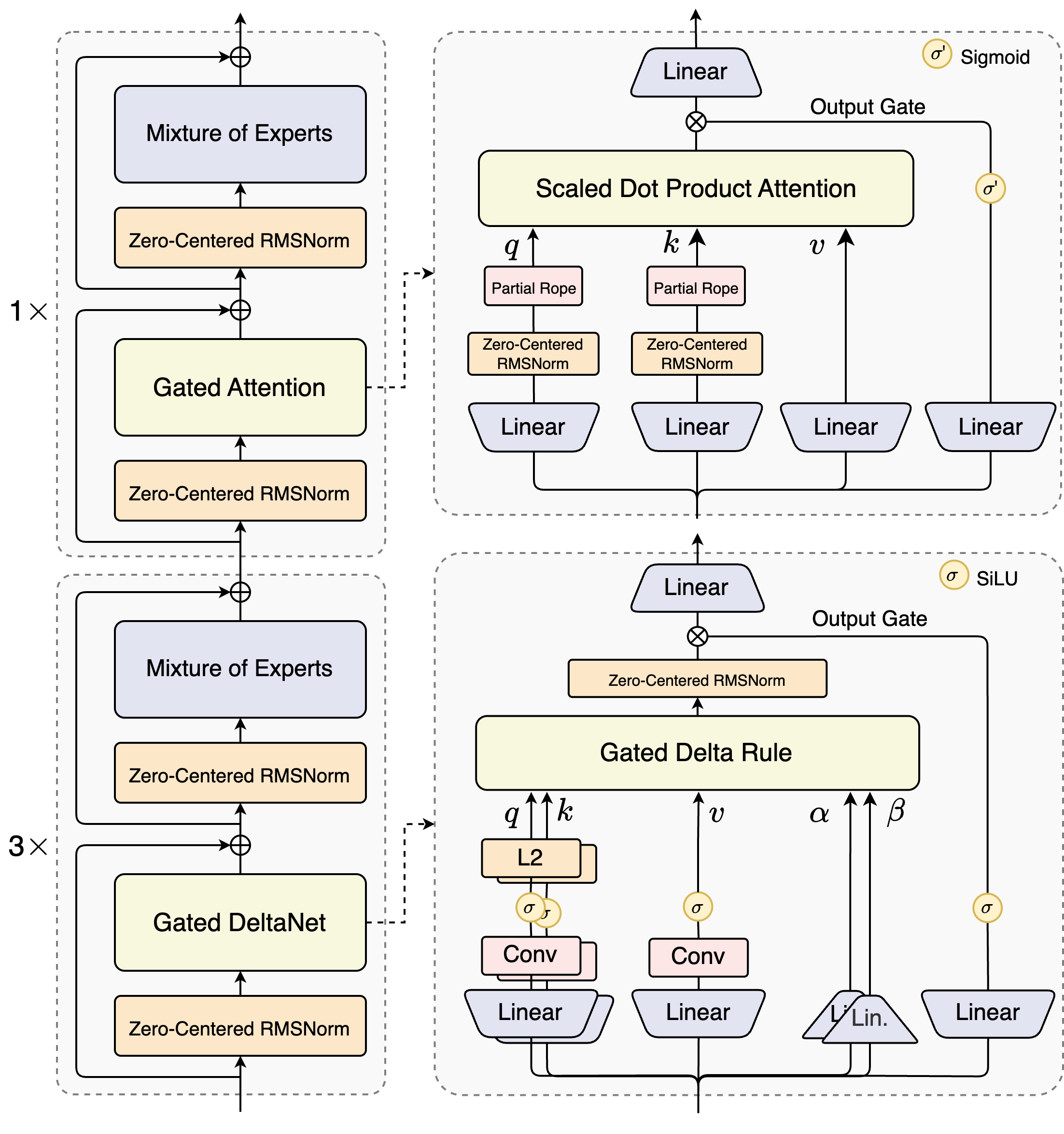 The hybrid architecture combines Gated DeltaNet (linear attention) with standard attention layers in a 3:1 ratio
The hybrid architecture combines Gated DeltaNet (linear attention) with standard attention layers in a 3:1 ratio
Training Efficiency Breakthrough
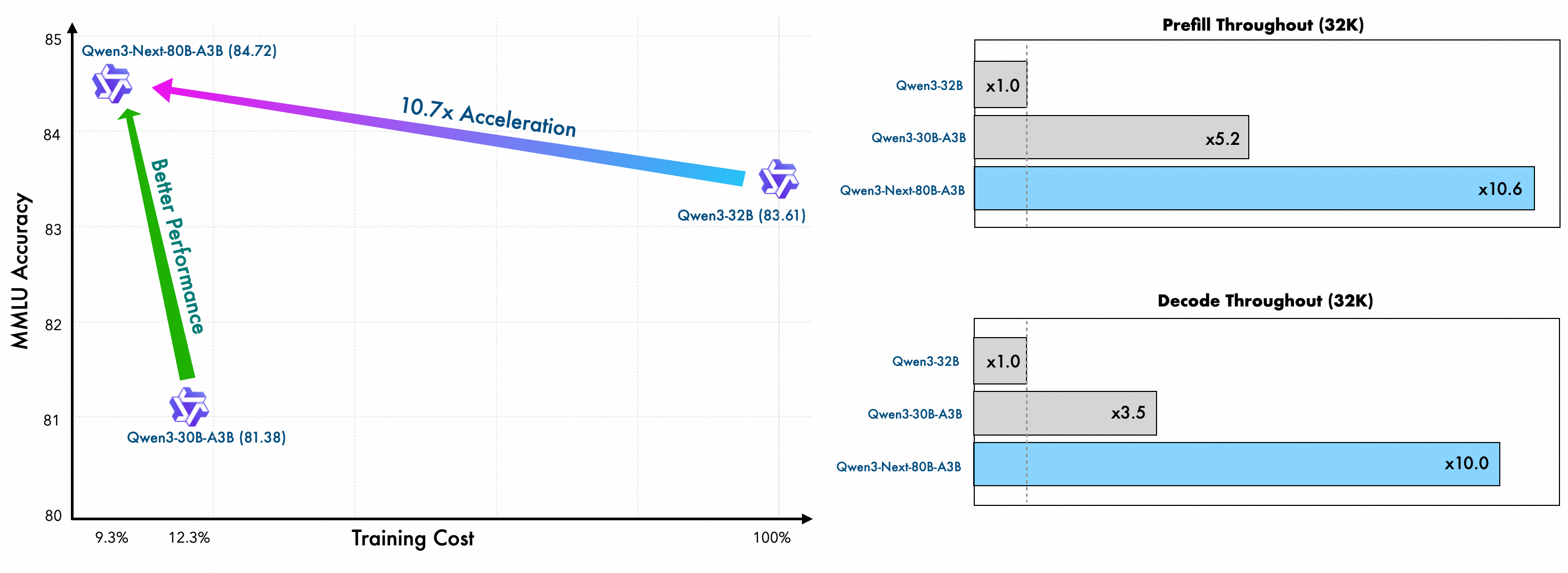 Training efficiency comparison showing dramatic reduction in compute requirements
Training efficiency comparison showing dramatic reduction in compute requirements
| Metric | Qwen3-Next-80B-A3B | Qwen3-32B | Improvement |
|---|---|---|---|
| GPU Hours | 9.3% of Qwen3-32B | 100% | 10.7x more efficient |
| Training Tokens | 15T | 36T | 2.4x fewer tokens |
| Performance | Better | Baseline | Superior despite efficiency |
Cost Example: If Qwen3-32B costs $100,000 to train, Qwen3-Next costs only $9,300 - a 90.7% cost reduction!
Inference Speed Revolution
Prefill Stage Performance (Initial Context Processing)
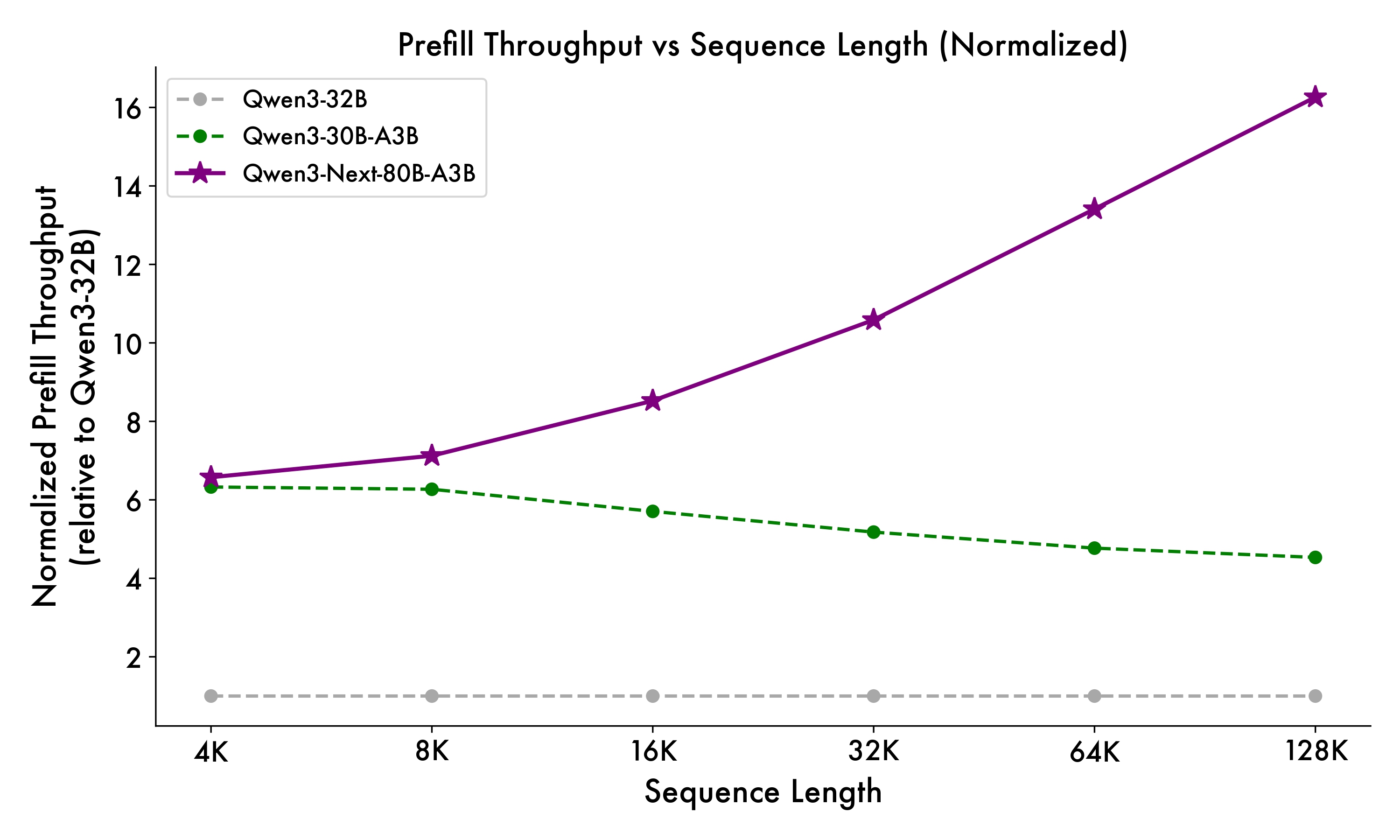 Prefill throughput comparison across different context lengths - showing dramatic improvements especially at longer contexts
Prefill throughput comparison across different context lengths - showing dramatic improvements especially at longer contexts
Decode Stage Performance (Token Generation)
 Decode throughput showing consistent advantages across context lengths
Decode throughput showing consistent advantages across context lengths
Reported Performance vs Qwen3-32B:
- 4K Context: ~7× faster prefill, ~4× faster decode
- 32K+ Context: >10× faster throughput
- 256K Context: Maintains >10× advantage
Benchmark Performance
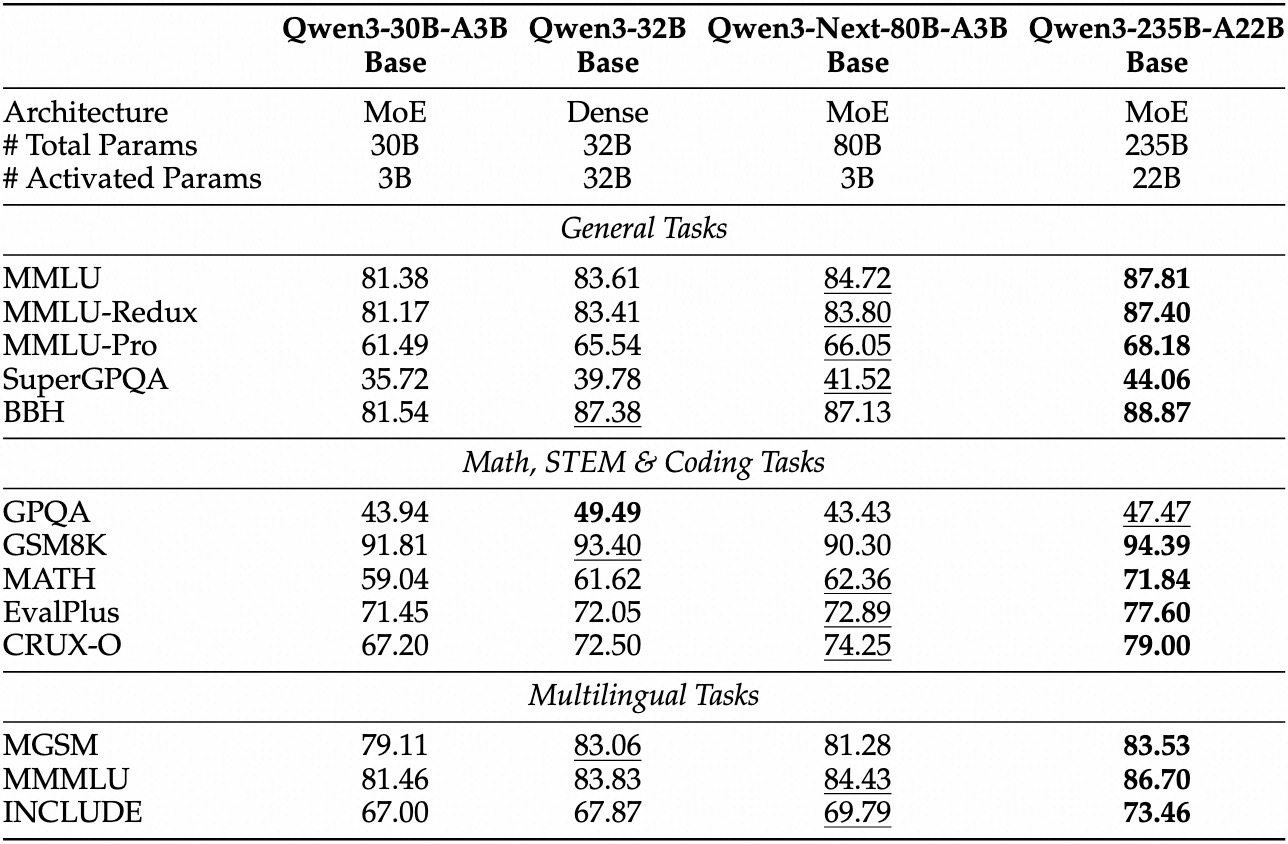 Comprehensive benchmark comparison showing Qwen3-Next outperforming larger models
Comprehensive benchmark comparison showing Qwen3-Next outperforming larger models
Long-Context Mastery (RULER Benchmark)
 RULER benchmark showing exceptional performance at extreme context lengths up to 256K tokens
RULER benchmark showing exceptional performance at extreme context lengths up to 256K tokens
Paper Quote: “On RULER, Qwen3-Next-80B-A3B-Instruct outperforms Qwen3-30B-A3B-Instruct-2507 (which has more attention layers) across all lengths — and even beats Qwen3-235B-A22B-Instruct-2507 (which has more layers overall) within 256K context.”
Deployment Guide
Quick Start with SGLang (Recommended)
# Installation
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
# Launch server with 256K context, 4 GPUs
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server \
--model-path Qwen/Qwen3-Next-80B-A3B-Instruct \
--port 30000 --tp-size 4 \
--context-length 262144 \
--mem-fraction-static 0.8Hardware Requirements
Despite activating only ~3B parameters per token, all ~80B weights must be loaded for expert routing:
- Unquantized FP16/BF16 weights alone: ~160GB
- In practice: Start with 4× 40GB GPUs (A100/A800/H200)
- For smaller setups: Use quantization (INT8/INT4) or reduce context length
- Production recommendation: 4× A100 40GB or equivalent
Ultra-Long Context (>256K tokens)
Enable YaRN scaling for up to 1M tokens:
{
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
}Model Variants
Three Specialized Versions
- Base Model: Foundation (15T tokens training)
- Instruct Model: General-purpose assistant
- Thinking Model: Complex reasoning specialist
The Thinking variant notably outperforms Gemini-2.5-Flash-Thinking on multiple benchmarks while being fully open-source.
When to Use Qwen3-Next
Perfect For:
- ✅ Long-context applications (>32K tokens)
- ✅ High-throughput requirements
- ✅ Cost-sensitive deployments (with appropriate GPU infrastructure)
- ✅ Complex reasoning tasks (Thinking variant)
- ✅ Real-time inference needs (with tensor parallelism)
Not Ideal For:
- ❌ Edge deployment (use Qwen3-4B or Qwen3-14B for edge scenarios)
- ❌ Single GPU setups (requires multi-GPU for full model)
Troubleshooting & Tips
Common Issues
Q: “KeyError: ‘qwen3_next’” when using Transformers
pip install git+https://github.com/huggingface/transformers.git@mainQ: Server fails with 256K context?
# Start with smaller context
--context-length 32768
# Adjust memory fraction
--mem-fraction-static 0.9Q: Low MTP acceptance rate?
--speculative-num-steps 2 # Reduce from 3
--speculative-eagle-topk 2 # Increase from 1Q: CUDA OOM errors?
- Enable tensor parallelism:
--tp-size 4 - Use INT8 quantization
- Enable memory-efficient attention libraries
Performance Optimization
For maximum speed:
config = {
"tp_size": 4,
"context_length": 32768,
"mem_fraction_static": 0.8,
"enable_cuda_graph": True,
"speculative_algo": "NEXTN",
}Key Takeaways
Three Revolutionary Achievements
- Efficiency Breakthrough: Less than 10% training cost for equivalent performance
- Architectural Innovation: Hybrid attention solves linear vs. quadratic trade-off
- Practical Deployment: Production-ready with multiple framework options
The Future Impact
Qwen3-Next demonstrates that extreme efficiency and high performance are not mutually exclusive. This architecture paves the way for more accessible and sustainable AI deployment at scale, influencing the development of Qwen3.5 and beyond.
The model’s ability to match dense 32B model performance while activating only 3.75% of its parameters represents a paradigm shift in how we think about model scaling. We’re no longer bound by the traditional trade-off between capability and efficiency.
Resources & References
Official Resources
Key Papers
- Gated Delta Networks (ICLR 2025)
- Gated Attention for LLMs - Non-linearity, Sparsity, and Attention-Sink-Free
- Multi-Token Prediction
- YaRN: Efficient Context Window Extension
- Efficient Streaming with Attention Sinks - Stability analysis
- Massive Activations in LLMs - Numerical stability
Implementation Frameworks
- 🚀 SGLang - Recommended for production
- ⚡ vLLM - High-throughput serving
- 🤗 Transformers - Easy experimentation
- 🔧 Qwen-Agent - Agentic applications
This deep dive is based on the official Qwen3-Next release documentation and my analysis of the architecture. The efficiency gains are real and reproducible - this isn’t just incremental progress, it’s a fundamental leap forward in how we build and deploy large language models.